Hey there CF-Do-er,
It’s Robin from CFD Engine & this week I’ve mostly been wondering what to do with myself now that my homeschooling “skills” are no longer required – maybe I should do some CFD? 🤔
One aspect of my process, that I’ve not written much about, is that I do everything on the cluster, or in my case on the AWS instance.
I mesh in parallel, solve in parallel and export in parallel, the only thing that I don’t run in parallel is ParaView (more on that later).
I’ve had a couple of conversations recently that suggested that this approach might not be as common as I’d thought.
Let me explain it a little bit in this email.
A typical run
Almost all of my CFD runs go something like this:
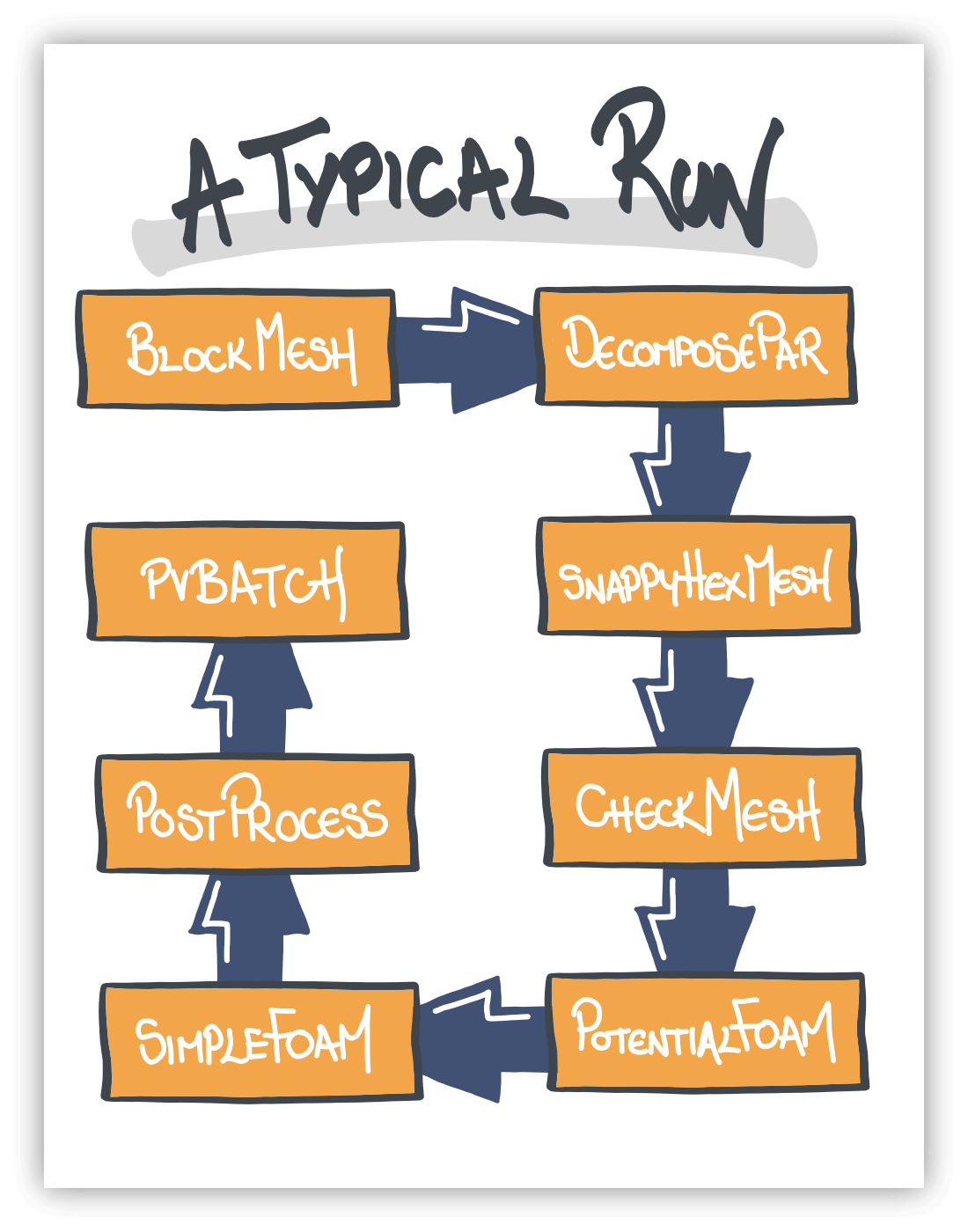
They’re all run on the cluster/instance, & everything between decomposePar & pvbatch runs in parallel.
The main drivers for doing everything in one place are speed, simplicity (of process) & a common data location. I’ll outline each of main phases of the run, out of sequence, and give you an idea why I do it like this.
Solving
The longest (& therefore most expensive) part of my typical CFD runs, so it makes sense to optimise around this phase.
I know the scaling can be a bit off, & that it’s very hardware dependent, but the fastest way to solve a case is generally using the maximum number of physical cores you have to hand (not threads – never threads).
numberOfSubdomains = number of cores & we’re good to go.
Quick Question: Do you use the OpenFOAM
RunFunctions–runParallel&runApplication? You might have seen them in the tutorials where they handle the mpirun command line, record output to a log file & won’t run if the log is in place. I use them all the time, just wondered if anyone else did 🤔
Exports
As I mentioned last week, I tend to export the post-processing assets I need (streamlines, slices, surfaces) from OpenFOAM, as opposed to generating them in ParaView. The export tools all work in parallel (AFAIK) & so there’s no need to reconstruct the model just to export stuff. Most of them also output serial assets, which makes #ParaViewLife much easier.
ParaView / pvbatch
This is the exception to my “do-everything-in-parallel” rule.
As I’m working with lightweight serial assets (as compared to tens of millions of volume cells) I could generate the images & animations on a much smaller machine. I don’t, because it’s simpler to run them straight after the exports have finished & because they finish in less time than it would take me to transfer the job & the assets to another machine.
Meshing
This is a trickier choice.
snappyHexMesh doesn’t scale as well as the solvers and it’s slower than many people expect (especially if they’re coming from another code). It’s also pretty greedy when it comes to memory. I’ve been caught out before when I couldn’t build the model I wanted because it needed more memory to mesh than it would’ve needed to run.
This feels like an ideal candidate for running on a different machine. One with loads of memory & a moderate number of cores (i.e. less than you’d choose solve on). But I still don’t think it’s a great solution (unless its the only way you can get it done).
Just like the solve phase, the fastest way to get a mesh out of snappyHexMesh is to use all of the cores you have available (not threads remember). But be prepared for it to take longer than you thought.
That’s why I mesh on the cluster/instance & I use the same number of cores as I’ll run on. It’s faster than meshing in serial and decomposing. And simpler than meshing on a different number of nodes and re-decomposing (or worse reconstructing and then decomposing) 🤯
This part of the process would look very different with a node-locked commercial mesher (or one that only meshes in serial). In that case, it makes perfect sense to mesh on a different machine & keep your license costs in check.
Could do better?
It’s not an optimum arrangement, but nothing about my process (or my CFD) is. It’s an 80/20 thing. I could definitely shave a few mins off an overnight run by making the process much more complicated, but I’m not here for that.
Functionality & simplicity are the name of the game. I’ll settle for “wasting” the computer’s time (& my money) over wasting my time, any day.
Some of this will likely be specific to my process & to running in the cloud. But your process probably isn’t that different. Do you do it all in one place? Or do you have specific mesh-ing & post-ing machines? Maybe you do something completely different?
I’m keen to hear how you make it work, especially if I’m missing something cool – drop me a note anytime.
Until next week, CFD safely,
